

Information Architecture
 Joe Schaefer
Joe Schaefer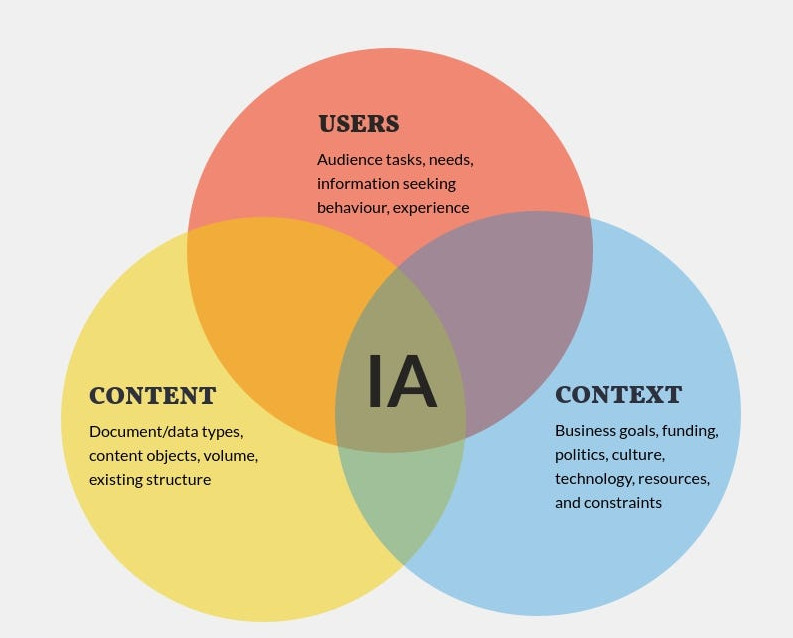
- Introduction
- Usability, Discovery, and Link Topology: the Big Picture
- Contrasting Heirarchies with Tagged Search
- Radically Rearchitecting Wiki Search
- Human Interface Goals
- Powerful Syntax
- Hashtagged Seaches are Keyword Specific Instead of Generic Word Searches
- Easy Scope Expansion
- Interactive Results Filtration Engine
- Built-In Performance Scaling to 100K document trees
- Comprehensible Result Ordering / Prioritization
- Per-User Security (ACL) Contextualized Results
- Hits Linked Directly to Target-Specific Document Locations
- Live, RealTime Results (aka No Stale Indexed Corpus)
- Customer Adoption Goals
- Deliverable as “application/json” Upon Request
- Styling is Semantically Controlled by Customer Installation of the
/content/css/boostrap.min.cssFile search.htmlTemplate is Overridable by Customer Installation of the/templates/search.htmlFilemain.htmlDerived Template is Overridable by Customer Installation of the/templates/main.htmlFile
- Human Interface Goals
- Radically Rearchitecting Wiki Search
- REST, HATEOAS, and Content Negotiation
- Beautiful URLs — Both Permanent and Transient
- Structured, Future-Proofed MultiMedia Content
- Access Controls on Content, from a Single Source of Truth Perspective
- SunStar Systems’ Orion™ for ZFS-backed Platforms
- StageMaster: Experimentation with Pure Client-Side State Engine
- GitOps build workflows
Introduction
Information Architecture organizes and arranges the entire gamut of technologies relevant to the design, presentation, relationships, and architectural constraints that cover every URL you serve over HTTP, both publicly and privately. This essay is a high-level survey of my expertise in these areas; it is far from comprehensive given the vast field it intends to cover.
Usability, Discovery, and Link Topology: the Big Picture
Contrasting Heirarchies with Tagged Search
Radically Rearchitecting Wiki Search
Human Interface Goals
Powerful Syntax
Hashtagged Seaches are Keyword Specific Instead of Generic Word Searches
Easy Scope Expansion
Interactive Results Filtration Engine
See the section on HATEOAS for an overview.
Built-In Performance Scaling to 100K document trees
Comprehensible Result Ordering / Prioritization
Per-User Security (ACL) Contextualized Results
Hits Linked Directly to Target-Specific Document Locations
Live, RealTime Results (aka No Stale Indexed Corpus)
Customer Adoption Goals
Deliverable as “application/json” Upon Request
Options:
- pass “as_json=1” in the query string
- set “Accept: application/json” in the request headers
Styling is Semantically Controlled by Customer Installation of the /content/css/boostrap.min.css File
search.html Template is Overridable by Customer Installation of the /templates/search.html File
main.html Derived Template is Overridable by Customer Installation of the /templates/main.html File
REST, HATEOAS, and Content Negotiation
Beautiful URLs — Both Permanent and Transient
Structured, Future-Proofed MultiMedia Content
GitHub Flavored Markdown with and Mermaid.js Integration
YAML Headers for MetaData
A Turing Complete Programming Language Ain’t Data - it doesn’t belong in your content sources
The Value of Enabling Template Preprocessing on Content
Inline Data Processing Engines
- embedded, “safe” json literals in built files
- build-time markdown table generation
Slowly Evolving, Centralized Configuration of Wiki Facts
- corporate service urls
- software artifact locations and version numbers
The role of ssi Tags in Your MultiMedia Strategy
Access Controls on Content, from a Single Source of Truth Perspective
walk_content_tree()inpath.pm- acls
- dependencies
acl.yml
SunStar Systems’ Orion™ for ZFS-backed Platforms
- zfs clones
- zfs send/recv
StageMaster: Experimentation with Pure Client-Side State Engine
GitOps build workflows
- Frontend
- Backend
- Documentation